Multiline Ultimate Assembler (an x64dbg plugin)
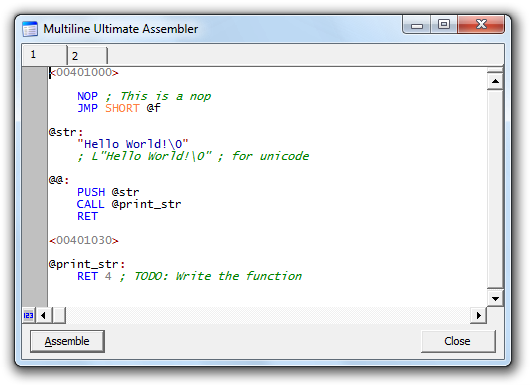
Multiline Ultimate Assembler is a multiline (and ultimate) assembler (and disassembler) plugin for x64dbg and OllyDbg. It’s a perfect tool for modifying and extending a compiled executable functionality, writing code caves, etc.
Download
![]() multiasm.zip (682.71 kB, changelog)
multiasm.zip (682.71 kB, changelog)
Latest version: v2.3.8
Source code
Posted in Releases, Software by Michael (Ramen Software) on September 13th, 2009.
Tags: multiline ultimate assembler, ollydbg, x64dbg
Tags: multiline ultimate assembler, ollydbg, x64dbg
i really like that plugin, but sometimes for no reason, it doesn’t want to accept strings – the example like on this page wouldn’t work, it would give me a ‘command mnemonic expected’ in the middle of “hello world” string.
just ignore previous comment, i didn’t see i don’t have the latest version 🙂
How do i plugin on ollydbg? I’ve put the plugin in plugin folder but it doesn’t appear on olly. Should i set something on ollydbg.ini? -Thnx- nice blog
It should just work.
You can upload your olly pack so I could check it out.
AWESOME!! This plugin would’ve saved me a lot of time on multiple occasions.
Very useful. But it crashes almost everytime.
It writes the opcodes just fine, but then crashes Olly a few seconds later.
Okay, I’ve pinpointed it to Labels.
If “Write Labels” is enabled in options, it crashes me Ollydbg (1.10 – Tried clean install too).
If I untick “Write Labels” it works just fine.
PS: I can’t get it to support labels for loop instructions (LOOP, LOOPD, LOOPE).
@Bla:
LOOP @Bla ; does not work
LOOP 00401000; works
Confirmed
LOOP SHORT @Bla ; works
^ you can use this form meanwhile
I’ve never experienced such crashes. You say it happens with any code/binary even on a clean olly? Can you say on which RVA it crashes?
After a number of experiments, I was able to reproduce the issue. Seems like it’s a bug of Ollydbg and it’s Quickinsertname/Mergequicknames functions. Maybe Ollydbg does not expect these functions to be called from another thread – what MUltimate Assembler does.
It does not crash on my PC while assembling a sane amount of code, but inserting labels/comments in a loop make it eventually crash.
Perhaps your PC is faster, and thus it happens regularly for you.
Disabling “Write Labels” and “Write Comments” will help, but if you find these useful, you could make MUltimate Assembler use Insertname instead of Quickinsertname/Mergequicknames (Insertname accepts the same parameters as Quickinsertname). As an Ollydbg user it should not be difficult for you 🙂 Try it and tell me how it works.
The crash was fixed in v1.3
Updated to v1.2.1
Bug fixes:
– Now correctly assembles loop instructions with labels (reported by Morten).
– Fixed assembling short jumps with labels on high addresses.
Updated to v1.2.2, which only creates a single thread on startup and uses it instead of creating a new thread every time the assembler window is opened.
That makes it work together with the phantOm plugin.
Great Plugin!!
Thanks!
Thanks for the update. Disassembler is awesome! Still waiting for tab renaming feature, though. 🙂
nice plugin as say MCKSys Argentina ,, i use from version 1,
ask: is posible do this same for ollydbg 2 ( now was a update and cann add plugin ^^)
BR, Apuromafo
I want to eventually update it to OllyDbg 2, but for now I think I’ll wait for a documentation of the API.
^^ now was a little documentation in ollydbg.de maybe you can check if are good or not 😀
Best Regards Apuromafo
It’s very partial, and lacks important functions such as Assemble.
u.u oki , i hope see some day this plugin in ollydbg 2 😀
Done!
this is my fav olly plugin, not to seem ungrateful but I think it will take some time for the plugin documentation to appear..and its a real pain having to juggle multiple versions of olly ..as v2.0 is the best now even tho a little buggy
thanks for your work
v1.7.1:
* Search/replace in editor (hotkeys: Ctrl+F, Ctrl+H, F3, Shift+F3).
* Fix: Correctly handle prefixed instructions (LOCK, REP, REPE/REPZ, REPNE/REPNZ).
Just came across your amazing plugin. It is a life-saver. I am doing a tutorial on code caves right now and I can’t wait to introduce your plugin to my many readers.
I have one feature request. Seeing as a lot of the members on my site are beginners, it would be great if, instead of just giving a generic error, your plugin said what line number the error was on or highlight the line or something. I can already tell I’m going to get numerous questions like “Can you look at my code? It says I have a ___ error but I can’t figure out where”.
Anyway, if you have the time. If not, it’s still an amazing plugin and I will use it often.
I am also going to ask my minions to donate to your cause, as I plan to do as well. Too few people get recognized for their hard work.
-R4ndom
Hi R4ndom,
Thanks for the feedback.
As for the error spot, after showing the error message box, the caret moves to the line that contains the error.
RaMMicHaeL.
http://thelegendofrandom.com/blog/archives/2470
btw: do you have any sort of manual or quick guide or anything? I would love to include something in the tutorial…
Nope, though I do plan to write a help file to make things clearer once I have some spare time.
Done!
Может быть вам стоит рассказать об этой штуке на Хабрахабре? Там очень большая аудитория, и статьи на подобную тематику воспринимаются очень тепло. Пример: http://habrahabr.ru/post/51857/
Также вы можете рассказать о 7TT, рассказав для примера как вы делали какую-нибудь простую функцию (чтобы не посчитали рекламой и воодушевить других программистов). Это будет просто бомба! 🙂 Ну и +10 к популярности вашего ПО. Для примера, моя последняя статья ( http://habrahabr.ru/post/168269/ ) за 10 часов уже собрала больше 25000 просмотров — а это немало.
Страна должна знать своих героев! 🙂 Если надумаете что-нибудь написать и оценить Хабраэффект, я могу поделиться инвайтом.
Может быть, хотя не уверен, что из меня выйдет хороший писатель. Да и время для этого найти нужно.
А вообще я с Хабром знаком, почитываю иногда.
Про 7TT, кстати, кто-то уже писал (кратко, но все же):
http://habrahabr.ru/links/125911/
Ну а так, если надумаю писать, буду знать к кому обращаться за инвайтом. Спасибо за предложение 🙂
Это не считается, поскольку заметка даже на главную не попала. Секрет успеха на хабре — немножко подробностей, как оно работает. А там где вы показали кроме ссылки ничего нет.
Что касается написания статей. Нужно просто написать пару первых предложений — остальное уже как-то само получается 🙂
Вот, накатал статейку:
Здесь была ссылка
Ваше мнение?
Ответил вам по почте. Кстати да, это вы мне написали, или кто-то другой подсуетился? 🙂
Я, кто же еще 🙂
Hi,
Would it be possible to also compile this plugin as a standalone DLL/static library? This would help with writing tools that need to inject code for example.
Please consider it.
Greetings,
Mr. eXoDia
Hi Mr. eXoDia,
The plugin uses OllyDbg’s assembling and disassembling API, so it can’t be made standalone. Have you considered using FASM or similar?
RaMMicHaeL.
Thanks for the reply! Yes I considered fasm, but your plugin just rocks..
And does your plugin only rely on this library or also on other parts of olly (only a dll that assembles is good enough) because disasm is open source: http://ollydbg.de/srcdescr.htm
Greetings
Here are the functions it imports from Olly:
Addtolist
Pluginreadstringfromini
Findmemory
Findmodule
Finddecode
Pluginreadintfromini
Readmemory
Disasm
Assemble
Dumpbackup
Plugingetvalue
Getstatus
Findsymbolicname
Pluginwriteinttoini
Writememory
Quickinsertname
Pluginwritestringtoini
Mergequicknames
Deletenamerange
Findname
So no, not much
But it’s designed to assemble code to memory. You want a standalone library to write code to a file, right? If so, the division to sections (<401000> stuff) would either dropped, or I’d have to use a custom file format or something.
In any case, how would that be better than FASM?
In addition, FASM supports macros, which are very powerful and might come in handy.
P.S.
Thanks 🙂
the sections () would not be used with my code.. It’s more like this:
unsigned int makeinline(unsigned char* result, char* assembly, unsigned int va_base)
result is the resulting assembly code
assembly is just the plain text code (with @label, “\x03” support)
va_base is the virtual address where the result will be written later on
return value is the length of the resulting buffer.
For me it’s more about the simple syntax and compatibility with the odbg version of multimate assembler.
Something optional would be that the function also returns a relocation table, but for me it’s mainly about the code style.
Greetings
Let’s make a deal 🙂
I make the standalone library you requested, and you write an article about how you use it, what it’s good for, etc.
I’ll post your article on my blog, so others can see what it’s all about, and maybe use it too.
What do you think?
Deal 🙂
Here you go:
https://www.dropbox.com/s/3rbmow07ng6n5k0/Multiline%20Ultimate%20Assembler%20library.rar?dl=1
See header file for exported functions and documentation.
See demo project for usage examples.
One downside is that the available OllyDbg (dis)assembler sources don’t support operands such as DB, DW, DD, which are very useful sometimes.
Thanks! I’ll be making a little (open source) tool that shows the usage of this library and include an article about how it all works with it..
Greetings,
Mr. eXoDIa
Hello again.
I’ve been trying to get it to work with ollydbg 2. I’ve downloaded the latest version and placed multiasm_odbg2.dll in ollydbg2\Plugins, and set up the plugin directory in the ollydbg options.
However, the Plugins menu is grayed out, and the plugin doesn’t seem to load at all.
Reading on ollydbg2.de it seems he changed the plugin interface, so I guess it’s incompatible with the new version.
Any chance of an update for the latest version of ollydbg2?
Thanks.
Hmm, downloaded the second latest version of olly, and now it works. Guess I’ll just stick with that one for now.
Hi,
The latest version, v2.1.1, is compatible with the latest version of OllyDbg, odbg201h.zip (November 19, 2012). Just rechecked it.
Could it be that you’re trying an older version of the plugin?
Hmm. Weird. It works now. I redownloaded olly 201h and MUA v2.1.1 from the top of the page.
Though I’m certain that it’s the same versions I used before. Perhaps it’s some ollydbg settings. I’ll poke around.
Thanks.
it has to do with ini settings of ollydbg. just delete ollydbg.ini to fix this issue…
greetings
Hey,
I’ve been busy with this standalone library, but currently real life stuff is eating all my time… I’ll continue writing the tutorial, but it might take more time.
Greetings
Fine, thanks for letting me know. Tell me if you need any help with the library.
Hey,
So I had some time to ‘finish’ this coding example of your library so here it is: http://rghost.net/private/45983365/f6fdd54ba9db02e63867bf1fe66ab2c7 I still need to write a full tutorial in PDF format, but here is just what I could do by now (it works, tested on one target, but it works)
Greetings,
Mr. eXoDia
Nice 🙂
The technique mostly targets protectors, right?
I found a bug that caused it to crash on my PC, pefunc.cpp line 70:
psh=(IMAGE_SECTION_HEADER*)(&pnth->OptionalHeader)+pnth->FileHeader.SizeOfOptionalHeader;The pointer is not calculated correctly.
Also, it might be worth creating the extra section automatically.
Yes I think mostly for targeting protectors. But it could also be useful if someone wants to make a small disassembler with easy multiline assembling feature (although x64 would be better in that case).
Thanks, I reused the code from another project and it isn’t really used so I experienced no crashes. Fixing line:
psh=(IMAGE_SECTION_HEADER*)((DWORD)(pnth)+pnth->FileHeader.SizeOfOptionalHeader+sizeof(IMAGE_FILE_HEADER)+sizeof(DWORD));
I will see if I’m going to implement this feature.. usually I use titanengine, but in this case I would need to write this code by myself (no problem, but it takes time).
Greetings,
Mr. eXoDia
Hi,
Lately I was using multimate asm to do some relative coding in DLLs, but would it be possible to add a syntax for the module that you’re currently debugging?
Greetings
Hi,
Can you provide an example where this could be useful?
Not one that I can post directly here, but lets say I wrote a universal API hook that I wanna use on 50 files with dynamic bases…
Greetings,
PS I didn’t forget this promise on the article about the static lib…
here is the article
http://rghost.net/private/48928371/b49c97786059174bc94b044965e43d52
Thanks!
I’ll look at it tomorrow.
Are you OK with it being published as a blog post?
Also, I’ve noticed that Hooking_Example2.exe and Hooking_Example3.exe are equal.
Is Hooking_Example3.exe redundant?
First of all, are we talking about the plugin or the library?
How are you going to patch these 50 files? Not by hand I guess?
Currently you can do this, so the base is defined only once:
About the ollydbg plugin, For the library this feature already exists. The actual reason why I wanna use this is because a tool of mine retrieves data (CRCs) from a protected file and then auto-generates a multiasm file. The problem is that the module name is not always known (when the user does custom patches for example when he/she adds a section).
So that’s the reason 🙂 rest of your feature I’m using already (only defining the module base once), problem is that this explicit base address isn’t working on DLLs because the image base changes every time I load the target DLL in olly.
Greetings
PS That double is probably another test, redundant indeed. Go ahead with the publishing, I owe you that much..
So you’re generating an .asm file, and you want it to work for the user out of the box, without the need of adjusting the base address or module name. Right?
How about using an empty module name to refer to the module open in the debugger CPU?
i.e.:
Yea, that’s what I mean!
The article is also perfect and this recapcha thing would be appreciated 🙂
Greetings
Done!
http://rammichael.com/multiline-ultimate-assembler-library
Here’s how it looks:
http://dl.dropboxusercontent.com/u/57395470/Multiline%20Ultimate%20Assembler%20Library%20-%20RaMMicHaeL%27s%20Blog.htm
I’m waiting for your approval 🙂
P.S. Are you sure you want me to publish your email as is? I could put it behind reCAPTCHA, like I did for my email here, to minimize spam:
http://rammichael.com/about
Done in v2.1.2. From the help file:
thanks a lot! it’s working perfect
After using this plugin for a while to patch a program, I’ve noticed some things.
Some sort of align directive would be useful, allowing jump tables or floating point constants to automatically go to dword boundaries.
Some sort of “stop” directive might be nice, too. Something like:
some instructions
!stop ; if you get here, there’s too many instructions
The editor doesn’t like undoing in overwrite mode. For example, type in “ab”, turn on overwrite, go back and delete the “a”, undo and “a” replaces “b”.
A keyboard shortcut (Ctrl+D perhaps) to put the debugger back into focus would be really nice.
Thanks for the feedback.
I guess it can be useful sometimes, but It will complicate the syntax, and I’m not sure it’s worth it.
I remember somebody suggested a “bp” pseudo instruction, which will put a breakpoint on the following command. Perhaps something similar to C’s “pragma” directive is worth considering.
How will it know when there are too many instructions?
It might work like this, maybe:
!max_address(00401020)
I think it might be a candidate for a pragma-like directive as well.
I’m not the author of the editor component. I’m using RAEdit. You’re welcome to fix this and send me a pull request:
https://github.com/RaMMicHaeL/SimEd
That should be easy.
How about as an extension to the label format:
@label@align:would create@labelas a multiple ofalignbytes?Yeah, sorry, my example didn’t format right and there was no edit; I’ll try again.
<start>some instructions
!stop
So
stopis an address, not the literal word.Done.
Since you use a tag-like format for the address, how about this:
<start>
instructions
</stop>
I’ve just released v2.1.4, which fixes the editor bug (thanks for the fix!) and implements Ctrl+D.
As for the other two suggestions: I’ll add them to my TODO list 🙂
Yeah, that key’s much better than having to click the mouse or double Alt+Tab. But the undo fix has introduced another problem: you’ve spelt my moniker backwards in the changelog. 🙂
Oops, sorry for that. It will be fixed in the next version, unless you want me to release one just with the moniker fix.
About the align/stop suggestions, I thought about it some more, and here’s what I think:
I don’t like your suggestion of including aligning in the label (
@label@align:). Labels are just names, and IMO shouldn’t imply any data write/manipulation.Your suggestion of the stop address (
</stop>) is nice, but I thought it would be better to generalize such extras into a pragma-like thing, like I mentioned earlier.Such commands could begin with ‘!’. Examples:
I don’t really like the “assert_addr_na” (na – not above) name too much, but I couldn’t think of something both short and descriptive. Ideas are welcome 🙂
No, it can wait.
Fair enough, but it would have made dword-aligned strings much nicer to write.
@str1@4: "string 1"@str2@4: "string 2"
versus
!align 4@str1: "string 1"
!align 4
@str2: "string 2"
Would an expression work, making assert a bit more general?
>402000>nop
nop
!assert addr <= 402001
Something else that would be useful is an enhancement to anonymous labels, where each additional
@skips another label.je @@f ; jumps to second anonymous label...
jne @f ; jumps to first
...
@@: ; jne goes here
...
@@: ; je goes here
I think making
!align 4available, and making@label@4:a syntax sugar of it, with the note that it’s just a convenience and the two are not really related, is OK.I thought about it too, but first, it needs to be implemented. Second, is it needed at all?
What else is there to assert about besides addr? And why would you use an operator other than “<=”?
Is it worth the complexity? Why not just use a named label?
Is there an assembler which uses this syntax?
Okay, maybe approach it a little differently:
!stop_at 402001Ideally that would restore from where it started and tell you how far it went beyond the stop address (which is what it implies, whereas the assert just implies a warning and it’s up to you to find out how far it went and restore it).Is it worth the complexity?
It would be for me. You could always make things simple for yourself and send me the source…
Why not just use a named label?
Because then I have to think of a name. And it’ll show up in OllyDbg.
Is there an assembler which uses this syntax?
I just saw it recently, but don’t remember where. It was done with macros, possibly with fasm.
Yet another approach would be to turn the address into a range:
<402000-402001>.I don’t see how it’s different than !assert_addr_na, except the name. There’s no reason why the assert can’t show you an informative message, and move the caret to its location.
I don’t like the stop/stop_at names, as they are not descriptive. If you’d browse an asm source and see a “stop” command, I assume you’ll get confused.
Heh, I’ll keep that in mind 🙂
Well, macros are macros. Not all the things they allow you to do are useful.
I now like the range idea best, as that lets the assembler know ahead of time where it should stop. I’d say it’s also very similar to what you already do with the end-of-section, as I recently discovered.
If you really want to be descriptive, maybe it should be “Multiline not-as-Ultimate-as-all-that Assembler.” 😉
You’re talking about this message, right?
There’s nothing about “know[ing] ahead of time where it should stop” here. It just assembles the block, and then does the check. Otherwise, it wouldn’t be able to say how many extra bytes you have.
Perhaps the range syntax is indeed the better one, but I don’t like the fact that it uses ‘-‘, which could be interpreted as a minus. Perhaps it could look like this:
<00401FFE..00401FFF>It’s all relative. It’s not as flexible as e.g. FASM is, but it surely is ultimate comparing to what you have built in OllyDbg 🙂
That would be great.
I’ve implemented/fixed those in v2.2.
I did not do extensive testing, so please, try to feed the assembler with various invalid input and see whether it always works as expected. Tell me if it doesn’t. Thanks 🙂
Excellent, I’ll rearrange stuff again to take advantage of it and let you know how it goes. Now I can remove all those extra \0-s I’ve added to my strings (but to free up space in the code section, I’ve moved jump tables and float constants to padding at the end of .rdata, so with aligned strings everything else is already aligned).
(Why is it so hard to write backslash-zero? My string examples were supposed to end with it and the above backslash-s was supposed to backslash-zero-s, where I doubled the backslash.)
(Nevermind; I found out you need to use the entities “to work around kses”.)
FTFY. WordPress comments screw up sometimes. Perhaps I should try WP-Markdown.
It seems
@label@align:still assigns the pre-aligned address to@label.Should be fixed in v2.2.1.
Wow, you don’t muck about, I was hoping to squeeze in another request before the next update. Could you add Ctrl+B to the editor to toggle column selection (see
IDM_EDIT_BLOCKMODEinSimEd.asm– at least, I think that’s all you have to do)?Done in v2.2.2.
Thanks for the tip, I didn’t know it was built in with the editor component.
You can even draw with it 🙂
http://i.snag.gy/ux23W.jpg
The range is working a treat, although I keep getting caught out. E.g. it says two bytes over, so I tweak it, but then it says three bytes over – argh, look where the cursor is!
If I may make one more suggestion, perhaps recognise
jmp @e(e for end) and if it doesn’t fit, just nop it instead.I’m not sure I understand. Can you provide an example?
What I think might be a better idea is filling the unused bytes of the block with NOPs.
I need to think about a good syntax for it, though.
You place the cursor on the instruction that goes over, but I only look at that the second time. 🙂 So given
pop esi/ret 4, you’d tell me it’s one byte over (and leave the cursor on thepop), I’ll save one byte and now it’s three bytes over (with the cursor on theret 4, which now I notice.) That’s just my misunderstanding with how I want it to work and how it actually works.As for
NOP‘ing blocks, how about!pad [90]– 90 being theNOPopcode by default, but could also allow 0CC, or 00 for data areas. Or maybe!fill.Got it. What happens is that multiasm stops on the first command which exceeds the end address. You can enter nonsense on the end, and the plugin won’t complain.
http://i.snag.gy/IotEj.jpg
I can change it to work similarly to the way it works with end of memory – assemble all commands first, complain later. It will then know exactly how many extra bytes there are.
I think I could introduce both commands – !fill with two arguments: the amount of bytes and the byte value, and !pad with only the byte value. !pad will then only work if an end address is present.
Sounds good!
v2.2.3 improves the error message, and implements the !pad command.
Yep, that’s a better message, thanks. However, now if there’s another address after the range, the range is ignored.
<401ffe..401fff>&nop
nop
says 1 extra byte, but
<401ffe..401fff>&nop
nop
<402000>
assembles without warning.
Yep, you’re right. I keep making silly mistakes. Rapid release schedule FTW, huh? 🙂
Should be fixed in this version:
https://www.dropbox.com/s/hpc276czawvnm6l/multiasm_v2.2.3.1.rar?dl=1
That’s not an actual release as I don’t have access to the .chm compiler at the moment.
Nice to know I’m not the only one. 🙂
Yep, excellent!
Oh, so you just want
@eto be a special label that refers to the address after the last command of the block, right? Seems like I’ve misunderstood your suggestion. It seemed to me like you’re suggesting some kind of special case commandjmp @e, according to:I thought about another improvement, which may help here too, but is much more generic: implementing local labels. You could perfix the label with e.g. a dot, and it would apply only for the current block. For example:
<00401000> jmp @.e ; jump below nop @.e: <00401010> jmp @.e ; jump below nop @.e: <00401020> push @.e ; error, label is not definedPerhaps a better syntax can be introduced. I have to think about it.
No, you were right the first time – ideally I want the label (so it can also be used with conditional jumps) and a NOPable jump (to continue from the end of the block).
; patched code is smaller than original <401000..401010> jmp @e ;; jmp 401010 - skip remainder ; patched code is one byte smaller than original <401100..401101> jmp @e ;; nop - all that's needed ; patched code is same size as original <401200..401200> jmp @e ;; nothing at all - already thereLocal labels would be good, too (but they wouldn’t help with the above, since that effectively wants to jump outside the block). My preference would be either
@@local(MASM/TASM default) or, if feasible, just.local(NASM/FASM, which actually append to the previous global, so still accessible as@global.local, if you really want to be fancy).(Dammit, I just can’t win with WordPress. ;))
I think a directive would be better than the
jmp– how about!skip? If there’s no bytes remaining, do nothing; 1 to 6 bytes could use a suitable nop; otherwise justjmp.I’ve come across an “Internal error”. I was using unused .data for some variables, some of which I had initialized. I then remembered that that part of .data is really virtual, so I split it into two, placing the initialized stuff back in .text (as I’ll be writing it all back to the exe). To compensate I wanted to add the difference of the pointers:
push [dword ecx+@textvar-@datavar]. It’ll do the+@textvaror the-@datavar, but not both (OllyDbg itself assembles it).That’s an interesting issue, caused by a kind of a hack I use.
Consider the following example:
<00401000> jmp @next ; more code @next:When doing the first pass on the code, you see “jmp @next”, but you don’t yet know what @next is. It might result in a long jump or a short jump. But you have to know the length of the jmp command in bytes, in order to be able to calculate @next.
What I do on the first pass is replacing any label with the address of the command plus INT_MAX. So “jmp @next” gets assembled as “jmp 80400FFF”, making it a long jump. Then I know it’s going to be 5 bytes long, and I can proceed to the next commands.
On the second pass, when I know what @next is, I can assemble the real jmp command, which will always be long, whatever @next is.
With your code, gets assembled in the first pass as:
push [dword ecx+(addr+INT_MAX)-(addr+INT_MAX)]Which results in:
push [dword ecx+0]The zero is discarded and the command length becomes smaller than it needs to be. That’s why there’s an error on the second pass.
There are other possible issues with this hack technique, for example:
<80000001> PUSH @a <00401000> @a:But the code range of 80000000 +- FF is rare enough that nobody has noticed.
I need to think about it. One solution can be to replace every constant which is set by a label with a literal which fits only in a DWORD, -and- the difference between it and the current address also fits only in a DWORD. I don’t think OllyDbg is flexible enough to handle it.
Ideas are welcome 🙂
I had a look at how Playtime handles it and it turns out it doesn’t – not only does it barf when you give it two labels, a single label is generated incorrectly.
In my case, performing the substitution on the first pass would be sufficient (
@datavaris defined before thepush). Otherwise, maybe you could use a variable to store the offset, then reset it once it’s been used.int label_offset = INT_MAX;
// …
if (label) {
offset = addr + label_offset;
label_offset = 0;
}
The other option is to ask Olly to use (rather than ignore) the
LARGEkeyword to actually assemble the long form.Do you mean this?
http://code.google.com/p/ollydbg2-playtime/
I’m not familiar with it (and I don’t really know Lua). What relevant functionality does it have?
Yeah, but it must not be the case. The two labels could be defined below.
Do you mean for every command?
If I understand your suggestion correctly, this:
mov dword [@L1], @L2will turn to this:
mov dword [(addr+INT_MAX)], (addr)which might result in a short form. Also, you can still get a case where it fails, e.g.:
mov dword [(INT_MAX+addr_of_L1)-@L1], 1With this approach, it’s all about probability.
I’m not sure it has such a feature. Also, how could I get the difference between e.g.:
mov dword @L1, 401000and:
mov dword [401000], @L1Meanwhile, try this one:
https://www.dropbox.com/s/ddpvvrmmndf9vzi/multiasm_v2.2.3.2.rar?dl=1
It has some improvement to the hackfix. Not perfect, but should work for your case.
I’m not all that familiar with it either (nor do I really know Lua); I just knew it had an assembler, with labels, so I tried it out to see what would happen.
Well, that depends where you put the initializer. 🙂 But then, isn’t that okay anyway? No one’s going to generate code between -80..7F, so just using
addritself should be fine.I don’t follow what you’re trying to say. If you already know the address of
L1, why are you still addingINT_MAX? And@L1-@L1really should be zero, anyway.Indeed it does, thank you.
Yes, unless the command interprets the literal as a relative address. I’m not familiar with a command which contains two literals, and one/both of them is relative, but maybe there is one.
I meant the address of the command, not of @L1. Say, if the address of the command is 400000, and you write
[803FFFFF-@L1], it will become zero on the first pass, and non-zero on the second pass. The point is, whatever delta I choose, there’s always a range which will result in an error. To fix it properly, I’ll need to actually parse the command and understand the role of the labeled constants.Great. This one just adds extra 0x11111111 to every label.
If you were at all curious, here is what I was working on. (As it turns out, I rearranged stuff again, so ended up not using
!pad; could have used@e, though.)Yes, I was curious, and in fact I was about to ask you 🙂
The amount of code looks impressive. Seems like you’ve put quite a bit of effort into it. I did something similar with Resouce Hacker here.
Have you considered writing an article about it? I’ll happily publish it on my blog, if you’d like.
What makes it more useful than
!pad? It also turns into anopif the jump command doesn’t fit.That reminds me…
It’s bad enough writing a doc, I don’t wanna be writing more.
@ejust avoids having to type in the end address again. 🙂 It depends how you want to use it, I guess. There were only two places where I thought the patched code might be about the same size (one was one byte smaller, the other exact length; but both these cases ended up becoming redundant and I just changed a pointer, instead); every other place I was pretty sure was going to be smaller, so jumping out was assumed and padding was not necessary. BTW, adding the end address to the disassembler might be nice (perhaps as an option).На протяжении длительного времени я использую в работе этот прекрасный инструмент. Но обратил внимание на следующее. Первые несколько запусков плагин работает очень быстро, а затем начинает тормозить (начинает медленно открывать окно, долго выполняет захват выделенного кода, и т.д.). Такое ощущение, что он начинает (после нескольких запусков) усиленно поедать ресурсы, и, при этом тормозит не только сам плагин, но и отладчик OllyDbg. Приходится перезапускать отладчик, после чего плагин опять начинает быстро работать. Нельзя ли предусмотреть принудительную очистку памяти после закрытия плагина?
Ни разу не сталкивался с подобной проблемой.
Есть признаки кроме тормозов? Память, CPU?
Почему Вы решили, что проблема в Multiline Ultimate Assembler, а не в другом плагине, например?
I had a similar problem. Initially, it would assemble instantly (well, that’s how I remembered it, anyway). I then exited, deleted OllyMoreMenu 1.5 (I never used it and it interfered with Ctrl+O), restarted and it would take 19 seconds to assemble. I couldn’t put OllyMoreMenu back on, as I didn’t have a backup and couldn’t find it again, only 1.5+, which instantly crashed. It somehow resolved itself and now takes about 3 seconds to assemble (the somewhat bigger final version), although sometimes it was about 10 seconds (possibly with a “Not responding” message). Testing just now takes about 6 seconds.
The amount of time it takes to assemble is not the same issue as interface sluggishness (delay upon opening a window, upon disassembling, etc., which is what Valentin reports). Of course, this issue is not less important. I’ve never felt that it’s too slow, but on the other hand, I’ve never worked with files as large as e.g. your 2000-liner. I’ll experiment with large files and will see what causes the delay.
I took a look at it. On that occasion, I’ve got rid of an ugly hack: the plugin created a new thread for the GUI, mainly in order to call TranslateAccelerator and IsDialogMessage. That caused glitches and performance issues here and there, and could cause data races, as OllyDbg doesn’t guarantee thread safety for it’s API. In order to move the assembler to Olly’s thread, I had to use another hack, a small WinAPI hook, but I believe that it’s worth it.
As for performance: I did a couple of quick tests, using your FLStat.asm as a target, and here are the timing results on my PC with OllyDbg 2:
6515 ms. – overall assembling time with v2.2.4.
3579 ms. – overall assembling time with v2.2.5, out of which:
– 2469 ms. – assembling instructions using OllyDbg’s Assemble/Assembleallforms functions.
– 1094 ms. – writing memory using OllyDbg’s Writememory + Removeanalysis.
So as you can see, the bottlenecks now are OllyDbg’s functions, especially the assembler.
Quick test on my system with very rough timing: 2.2.4 – 4s; 2.2.5 – 2.5s. Nice!
Попробуйте, пожалуйста, версию 2.2.5.
Another thing that might be nice to have is the ability to split regions. For example, adding entries to jump tables, putting the new tables in unused space in .rdata.
<401000> jmp dword[eax*4+@table1] <rdata=402000> ;; create an alias for this region @table1: dd @addr1_0 dd @addr1_1 <401100> jmp dword[eax*4+@table2] <rdata> ;; continue where it left off @table2: ;; so this is at 402008 dd @addr2_0 dd @addr2_1That allows keeping related code & data together in the editor, even though they’re separate in memory.
Здаров! Тут такая трабла с последней версией плага, на Win 7×64 ru вываливается с ошибкой:
—————————
Multiline Ultimate Assembler error
—————————
Couldn’t find the TranslateMDISysAccel function in User32.dll
—————————
ОК
—————————
функция присутствует. версия библы: 6.1.7601.17514 (win7sp1_rtm.101119-1850)
у коллеги версия такая же винды, но версия библы: 6.1.7600.16384, и у него все запускается нормально.
предыдущие версии плагина запускаются нормально, проблема только в последнем билде. плиз пофиксь по возможности.
Здравствуй!
Не получилось воспроизвести. OllyDbg 1 или 2? Оригинальный? Другие плагины есть, без них работает?
пробовал на чистом оригинальном 1. на данный момент нет технической возможности обсудить данный вопрос подробнее. как только будет время и возможность, предоставлю все необходимое для попытки устранения данной несовместимости.
Все ок, была виновата сборка NiceDbg от SLV/ICU. До того, как посмотрел в эбаут, думал, что это оригинал)
Если возможно, пофикси горизонтальный скролл. Когда я добавляю большой массив байтов, то скролл не захватывает всю длину массива.
Можно ссылку? Интересно, что там происходит. Или приват? 🙂
Как это можно воспроизвести?
В целом, плагин использует компонент RAEdit, исходники которого можно найти здесь (и отправить пулл реквест):
https://github.com/RaMMicHaeL/SimEd/tree/master/RAEdit
Вот сборка + скрин скролло
rghost.ru/57884230
Плагин не работает со сборкой потому, что Оля сжата, и в таблице импортов нету функции TranslateMDISysAccel, которую плагин хукает. Я это исправил, фикс будет доступен в следующей версии, но если надо, могу выложить сейчас.
Насчет горизонтального скролла – похоже, эта фича просто не реализована. Так как компонент не мой, и так как мне это особо не мешает, исправлять пока не планирую.
Спасибо! Пересел таки пока на другую сборку)) А скролл не критично, просто в глаза бросилось. Отдельный респект за релиз для x64dbg!
I really like this plugin, but this plugin when writing the annotation does not support Chinese string, Chinese character display garbled.
Try changing the font in ollydbg.ini.
See also:
https://forum.tuts4you.com/topic/21128-multiline-ultimate-assembler/page-4#entry103871
Hi!
In my opinion Multiline assembler is the best plugin ever released for Ollydbg.
Many time I have renonced to patch a program coz when the patching job was a bit complicate, it was near to impossible follow the flux of the patched code…
BTW………
Do you thing in future will be possible to get a search and replace function in Multilne assembler?
Many thanks!!
dan
Hi Dan,
Thanks for the feedback!
There’s search and replace: Ctrl+H. See the help file for more hotkeys.
Thank you for the awesome plugin!
It seems the editor doesn’t really support non-ASCII characters, so for the time being I have to use unicode code points. You’re probably already aware of this, but if not, you can see this in the image below.
http://puu.sh/cTyy2/57c9829598.png
It’s not a huge issue or anything, it still works, but there you go haha.
The editor component (RAEdit) wasn’t written by me, and it’s a major task to update it to support Unicode, considering that it’s written in assembly. But if your system locale is Korean, I believe that changing the editor font can help.
See also:
http://rammichael.com/multimate-assembler/comment-page-1#comment-4579
Yeah I suppose that would be quite a task and it’s certainly not necessary since it is still possible to make use of Unicode should you need to do so.
Thank you for the advice though, I appreciate it.
Would I be correct to assume that RAEdit is open source? If that’s the case I might have to try my hand at implementing support for Unicode. I’m a little rusty when it comes to actually writing software in assembly, but it should be fun anyway.
Should that not work out, I suppose I could try asking the developer about it. I’d be willing to pay for it haha.
I see that you’ve already found the source code 🙂
Note that there’s also an automated C port of the codebase here (more details). The code cries for some refactoring, but in the end it might be easier to work with.
Indeed I did haha.
I noticed your port of the codebase to C and it should definitely come in handy. Thank you. 🙂
If I don’t manage to add support for Unicode to the original codebase, I’ll at least make sure to implement it in the C port and let you know. 😉
Actually, implementing it in the C codebase is a better option, since it will automatically work in the 64-bit version as well.
Of course! Perhaps I should have worded that last post a bit better haha.
I am planning on doing both, unless I fail to implement it in the original codebase, in which case I’d still make sure to implement it in the C codebase. 😉
This is really nice. Makes patching much easier, but…
It seems that the modifications created by assembling using this aren’t added to OllyDbg’s patch list, which makes managing them more difficult. I don’t know whether Olly gives any access to this list, but if it does, this would be a nice addition to this plugin 🙂
Thanks for the feedback.
The modifications should be added to the patch list. Which version of Ollydbg are you using?
Hi,
I’m using your plug-in with x64-dbg with a 64 bit application
It seems that the DB and DD commands are not recognised.
So far I have not been able to locate an equivalent command, do you happen to know the equivalent commands or do you know a command listing where I can find the answer.
BTW a very useful plugin.
Cheers
Hi,
Every line which is not a label, a comment, a string, or a “special command”, is treated as an assembler command, and is forwarded to the debugger’s assembler.
If you’ll try to assemble the “dd 00000000” command in the regular Ollydbg assembler, you’ll find out that it works. But it’s not supported by x64dbg.
For consistency, I believe that it’s something that is better to be implemented in x64dbg.
As an alternative, you can use the data string syntax for the plugin:
db 12 -> “\x12”
dd 12345678 -> “\x78\x56\x34\x12”
Hi RaMMicHaeL,
thank you sooooooooo much for this AWESOME tool … it really helps me a lot!
Recently I’m trying some assembling on x64dbg and, unfortunately, I discovered that – as far as I experimented – I can’t do math on labels.
I mean, on x86 I’ll usually write something like that
but if I try to assemble something like that with the x64dbg-plugin:
I got an error (or wrong result) on every instructions that does math on labels (failed to encode instruction) …
Is it the intended behavior and/or am I missing something?
In the meantime I’m doing something like that:
CALL @delta @delta: POP RBP ; Calculate "displacement" mov rax,@delta sub rbp,rax mov rax,@textSection add rax,rbp.. but I’d like to know if I could do labels’ math in some way or another 😉
Thank you for any help and/or hints … and please keep doing the GREAT work you’re already doing !
Best Regards,
Tony
Hi Tony,
Thanks for the feedback.
The plugin doesn’t do any math by itself. It just replaces the labels with the corresponding addresses, and passes the commands to the debugger engine.
If you’ll try to assemble the following commands in x64dbg, you’ll see that you’re getting the same errors:
add rax, 1234567812345678– an error.lea rax, qword [1234567812345678+10]– assembles tolea rax, [0x10], seems like a bug.lea rax, qword [rbp+1234567812345678]– an error.I’m not sure whether 1 and 3 are bugs, or whether the x64 architecture doesn’t provide these commands, but 2 surely is a bug of x64dbg.
Thanks again RaMMicHaeL for your quick and kind answer!
I’m afraid I was too rash and didn’t try to manual assembly-ing those commands … I’m really sorry for that.
It seems I’ve asked the questions to the “wrong” person … ehehhe. I’ll have to talk with Mr.eXoDia and here from him 😉
Best Regards,
Tony
I mean ‘hear’ from him
Practical post . Incidentally , you want a template form , my husband filled out and esigned a sample version here http://pdf.ac/9YSbzd.
I didn’t get it – what is the form about?
Any chance of warnings if calls/jumps are outside the region of code to be copied in the “Dissassemble selection” function?
Or is it intended not to be used as a plugin to copy assembly code?
You can use the plugin to copy assembly code, but I don’t plan to add such a warning. If I understand your goal correctly, you can use a regex to find such lines:
(call|j\w+?)\s+?(short\s+?)?[0-9a-f]{8}Ah okay, makes sense why not. I guess code/data copying would be best left to another plugin for that purpose.
Thanks for the regex hint though, I’ll try that 🙂
Hi Rammichael,
really love your plugin, I was wondering if you plan to fix some unrecognized assy op codes.
currently multi inline assembler does not recognize near calls to registers
eg)
FFD0 Call near eax
FFD1 Call near ecx
FFD2 Call near edx
FFD3 Call near ebx
FFD4 Call near esp
FFD5 Call near ebp
FFD6 Call near esi
FFD7 Call near edi
cheers
Hi Andrew,
The plugin uses the assembly engine of the host debugger, see here for more details.
As a workaround, you can use the bytes directly, such as:
db FF D0 ; call near eaxor:
"\xFF\xD0" ; call near eaxDear RaMMicHaeL, Please can you add following features to your tool . I am trying to get some function code from a dll (export) I select from beginning to end of ret where function ends but for unknown reason some jumps arenot dissambled , left original like jnz.RVA i think they are sub routines . Please can you make your tool disassemble those . please its a request .
Yours Lovingly ,
DibyaMSFN.
Hi Dibya,
Please provide a way for me to reproduce the issue. Upload the DLL, and provide a video, or at least a screenshot.
Shell32/ntdll of 8.1 . i need it to move some function to XP to run some apps .
like this one . My router broken i am browsing via my phone . I will upload those dlls if you want as soon as possible .
Code are coming like this you can find many calls , jumps,subroutines not got disassembled
MOV EDI,EDI PUSH EBP MOV EBP,ESP PUSH EDI MOV EDI,DWORD PTR SS:[EBP+14] TEST EDI,EDI JNZ SHORT @L00000001 XOR EAX,EAX JMP SHORT @L00000009 @L00000001: MOV EAX,DWORD PTR SS:[EBP+8] PUSH ESI TEST EAX,EAX JNZ SHORT @L00000002 XOR ESI,ESI PUSH ESI PUSH ESI PUSH ESI PUSH ESI PUSH ESI CALL $$6C61B ADD ESP,14 PUSH 16 POP EAX JMP SHORT @L00000008 @L00000002: PUSH EBX MOV EBX,DWORD PTR SS:[EBP+10] TEST EBX,EBX JE SHORT @L00000003 CMP DWORD PTR SS:[EBP+C],EDI JB SHORT @L00000003 PUSH EDI PUSH EBX PUSH EAX CALL $$703A0 (Not got disassembled) ADD ESP,0C XOR EAX,EAX JMP SHORT @L00000007 @L00000003: PUSH DWORD PTR SS:[EBP+C] XOR ESI,ESI PUSH ESI PUSH EAX CALL $$70A40 ADD ESP,0C TEST EBX,EBX JNZ SHORT @L00000004 PUSH 16 JMP SHORT @L00000005 @L00000004: CMP DWORD PTR SS:[EBP+C],EDI JNB SHORT @L00000006 PUSH 22 @L00000005: POP EDI PUSH ESI PUSH ESI PUSH ESI PUSH ESI PUSH ESI CALL $$6C61B ADD ESP,14 MOV EAX,EDI JMP SHORT @L00000007 @L00000006: PUSH 16 POP EAX @L00000007: POP EBX @L00000008: POP ESI @L00000009: POP EDI POP EBP RETNAnother
MOV EDI,EDI PUSH EBP MOV EBP,ESP PUSH ESI MOV ESI,DWORD PTR SS:[EBP+8] XOR EDX,EDX PUSH 1 MOV ECX,ESI CALL $$63544 TEST EAX,EAX JE SHORT $$5E7AD TEST BYTE PTR DS:[ESI+9C],1 JE SHORT $$5E7AD @L00000001: AND DWORD PTR DS:[ESI+9C],FFFFFFFD POP ESI POP EBP RETN 4one more
@TpAllocTimer: MOV EDI,EDI PUSH EBP MOV EBP,ESP AND ESP,FFFFFFF8 PUSH ECX PUSH EBX MOV EBX,DWORD PTR SS:[EBP+8] PUSH ESI PUSH EDI TEST EBX,EBX JE $$9465B CMP DWORD PTR SS:[EBP+C],0 JE $$9465B MOV EDI,DWORD PTR SS:[EBP+14] TEST EDI,EDI JE SHORT @L00000001 TEST DWORD PTR DS:[EDI+1C],FFFFFFFC JNZ $$9465B @L00000001: MOV EAX,DWORD PTR FS:[30] MOV EAX,DWORD PTR DS:[EAX+C] CMP BYTE PTR DS:[EAX+28],0 JNZ $$9465B MOV EAX,DWORD PTR DS:[$$0FBFEC] ADD EAX,100000 PUSH 0C0 OR EAX,8 PUSH EAX MOV EAX,DWORD PTR FS:[30] PUSH DWORD PTR DS:[EAX+18] CALL $$2ABF0 MOV ESI,EAX TEST ESI,ESI JE SHORT $$364B1 MOV EAX,DWORD PTR SS:[EBP+4] XOR DL,DL PUSH $$3AC8 PUSH $$3AB8 PUSH EDI PUSH DWORD PTR SS:[EBP+10] MOV ECX,ESI MOV DWORD PTR DS:[ESI+54],EAX CALL $$358D1 TEST EAX,EAX JS SHORT @L00000002 MOV ECX,DWORD PTR SS:[EBP+C] MOV DWORD PTR DS:[ESI+30],ECX MOV DWORD PTR DS:[EBX],ESI @L00000002: POP EDI POP ESI POP EBX MOV ESP,EBP POP EBP RETN 10Best of luCk .
Thanks a lot for your great tool
So, is this an example for what you think is an issue?
CALL $$703A0 (Not got disassembled)What would you expect to see instead?
I wish $$703A0 to be disassembled and be like @L00000001 so that i can trace code easily . please can you add the feature ?
Your lovingly ,
Dibya
If the target of the call is not part of the selected code, adding a label for it doesn’t make sense, unless I’m misunderstanding your problem.
It is not the part of selected code but it need for the code to work isnt it ? so i wish not to add label but to get disassembled the code . I wish the sub routines not in selected code to be disassembled .
OK, I understand your request now. I assume that it’s possible to implement, but this feature will have to rely heavily on analysis data. If the debugger won’t be able to detect the target command as a part of a function, or if it will be detected incorrectly, the feature won’t work very well.
For now, you’ll have to do it manually.
Okay . I hope i can get a update very soon .
Thanks in advance
Your lovingly ,
Dibya
Прикольно тема живёт.
К автору. Последнее время плагин чаще используется под отладчиком Диа. Там вроде поправили [rip+/-distance] на нормальное отображение указателей, у Вас осталось. Ну и второе, у Диа есть вызов плагинов, но как автоматом тыкнуть код в Ваш плагин пока не вкурю.
Что такое отладчик Диа?
Я не понял о чем речь.
Ок…не думал что так сложно.
Тогда на примере.
Просто копирую инструкцию в отладчике Mr.eXoDia x64 dbg как дизасм , вот результ:
LEA RCX, QWORD PTR DS:[141C914F0]
Делаю то же самое Вашим плагином.
lea rcx, [rip + 0x1c43239].
при переносе на другое место, в итоге указатель потерян.
По автоматике по электронке ответил.
На эту тему есть issue в трекере x64dbg.
“отладчик Диа” это x64dbg, получается?
это на днях пофиксили, так что это вопрос снят.
по автоматизации можно что либо решить ?
вызов плагина в скриптовом движке есть, и на мой взгляд ему достаточно передать три аргумента “откуда, куда, размер”, и можно ограничиться одним табом.
Речь об этом?
http://help.x64dbg.com/en/latest/developers/plugins/API/registercommand.html
да кажется оно, но тут только для скриптов, для вызова плагина ведь нужны же аргументы.
Добавил следующие команды:
multiasm_show, multiasm_disasm_selection, multiasm_close
https://exelab.ru/f/index.php?action=vthread&forum=3&topic=15003&page=5#27
Hey again.
Still an invaluable tool. However, there’s a really annoying bug in the 64-bit version for x64dbg. The text editor scrolls up when scrolling the mouse wheel down, so you have to use the mouse to drag the scrollbar, which is rather annoying (works fine in x32dbg).
Hi Morten,
A bug like this was fixed in v2.3.4. Are you using the latest version?
Hey.
About menu says v2.3.5.
I can’t reproduce the bug. It’s about scrolling with the mouse, right?
http://i.imgur.com/1SSXTzF.gif
MUA v2.3.5 and x64dbg v25: http://i.imgur.com/cCCk4FE.gifv
I can reproduce it with my touchpad, but not with the mouse. I’ll take a look
Okay, thanks.
Here you go, a 6-bytes fix 🙂
I’ll compile and publish a new version later.
The fix, in case you’re curious.
Cool, thanks! Works perfectly.
Yea, I was curious, thanks 🙂
I’ve released Multiline Ultimate Assembler v2.3.6, which officially fixes the issue.
Is there any way to get it to no put a lot of NOPs between instructions? I assume it’s some kind of alignment optimization, but in a lot of cases, I’d prefer compact code over fast code.
Are you using x64dbg? Are you referring to the NOPs after jumps?
x64dbg
0000000014001000 | 55 | PUSH RBP
0000000014001001 | 48 89 E5 | MOV RBP,RSP
0000000014001004 | 48 83 EC 30 | SUB RSP,30
0000000014001008 | E8 90 00 00 00 | CALL 1400109D
000000001400100D | 48 C7 C1 00 20 00 14 | MOV RCX,14002000
0000000014001014 | 90 | NOP
0000000014001015 | 90 | NOP
0000000014001016 | 90 | NOP
0000000014001017 | 48 C7 C2 00 30 00 14 | MOV RDX,14003000
000000001400101E | 90 | NOP
000000001400101F | 90 | NOP
0000000014001020 | 90 | NOP
0000000014001021 | 49 C7 C0 CF 00 00 00 | MOV R8,CF
0000000014001028 | E8 55 00 00 00 | CALL 14001082
000000001400102D | 48 C7 C1 00 20 00 14 | MOV RCX,14002000
0000000014001034 | 90 | NOP
0000000014001035 | 90 | NOP
0000000014001036 | 90 | NOP
0000000014001037 | 48 C7 C2 CF 00 00 00 | MOV RDX,CF
000000001400103E | 49 C7 C0 C0 31 00 14 | MOV R8,140031C0
0000000014001045 | 90 | NOP
0000000014001046 | 90 | NOP
0000000014001047 | 90 | NOP
0000000014001048 | 49 C7 C1 80 31 00 14 | MOV R9,14003180
000000001400104F | 90 | NOP
0000000014001050 | 90 | NOP
0000000014001051 | 90 | NOP
0000000014001052 | E8 02 01 00 00 | CALL 14001159
0000000014001057 | 48 31 C9 | XOR RCX,RCX
OK, I’m familiar with the issue. The reason for the behavior is that your constants are @labels, and the assembler cannot know their size beforehand, so it takes the worst case assumption.
For example, the command
MOV RCX,1234567812345678would take 10 bytes, not 7.See this comment for more details:
http://rammichael.com/multimate-assembler/comment-page-1#comment-3925
One solution for this is having a different syntax for shorter commands, something like
MOV RCX,DWORD @address. That’s being done for jumps actually, havingJXX @addressandJXX SHORT @address.If you have a better idea, let me know. Otherwise, this has to be changed in the assembler/disassembler engines of x64dbg (unless I add a special case in the plugin, which I’m reluctant to do).
Hmm. I see the problem.
jmp @Label@Label:
You’re assuming the JMP is 5 bytes, since you don’t know where @Label is before you encounter it.
Which results in:
14001000 | EB 03 | JMP14001002 | 90 | NOP
14001003 | 90 | NOP
14001004 | 90 | NOP
14001005 Label: | 90 | NOP
Couldn’t you do many passes to correct a bad assumption?
For example, imagine 2 scenarios.
Scenario 1 (Short jmp):
<14001000>jmp @Label
@Label:
On the first pass, when you encounter ‘jmp @Label’, you’ll start by assuming a short JMP is enough.
So you allocate 2 bytes for that.
Now you encounter @Label, and you realize 2 bytes were indeed enough. Then you assemble, and it’s perfect.
Scenario 2 (Far jmp):
<14001000>jmp @Label
<14004000>
@Label:
On the first pass, when you encounter ‘jmp @Label’, you’ll start by assuming a short JMP is enough.
So you allocate 2 bytes for that.
Now you encounter @Label, and you realize 2 bytes is not enough (requires 5),
so you restart the whole thing from the jmp instruction and change it to 5 bytes.
Now you encounter @Label, and now 5 is enough. Then you assemble, and it’s perfect.
Something like that.
It’s possible theoretically, that’s what FASM does. Read about “multiple passes” here. That doesn’t look trivial to implement, and I don’t plan to work on it in the foreseeable future, sorry.
If you would like to try implementing it yourself, I may consider releasing the source code.
Привет!
При реверсе в x64dbg наткнулся на инструкцию ‘push rbp’, состоящую из двух байт:
40 55 | push rbp
при дизассемблировании в multiasm, да и отладчик точно так же понимает, инструкция ‘push rbp’ при выносе ее в другое место состоит из одного байта 55.
По факту теряется байт 40. Не знаю, в чем отличие одно и двухбайтовой инструкции push rbp, но заметил недавно такой ньюанс. Как код в виде байтов передать знаю, но хотелось бы знать, есть ли в этом реальное применение.
Привет! Похоже что здесь есть ответ на вопрос.
спасибо!
Hello,
I’m trying to write a patch using RVA
Version of Multimate is v2.3.6
x64dbg – x32 – Jul 1, 2021
Base : 0x21000
Patch : 0x338B56
So I use
$.317B56
I get error: Address expected
Am I doing something wrong?
PS: Using absolute addresses works.
Hi,
In which command/context is
$.317B56used? Please post your whole code snippet so that I’ll be able to reproduce the error. Note that the$.<address>form uses the base address based on the module that is currently viewed in the debugger’s CPU view.Hello,
$.317B56 is within the .text section of the exe that I’m attempting to patch.
If I specify the absolute value instead, as a test, then it works and inserts the code
I’ve also tried $.1000, and get same error.
You should be able to reproduce the error using
$.1000
NOP
Did you leave out the
<,>characters by mistake? Perhaps they were stripped by the blog.In any case, it works for me: https://i.imgur.com/WRnbpNW.png
The “Address expected” error message is shown if the first character is not
<.Hello,
Yes I did leave out the <> characters by mistake
I was following the example in the Help file literally
Perhaps you could consider updating the example in the help file to show as
<$.1000>
Thanks for your prompt reply
Multimate is a really useful plug-in.
Cheers
VW
Hello! My friends and I really like your plugin. It has allowed for much faster modification of an existing executable, compared to assembling instruction-by-instruction. The biggest (if not only) thing that we think it’s missing are macros of some sort — %defines or the like that can be used for simple inlined text replacement before it gets assembled, like the preprocessor in nasm. Would you pass us the source to this plugin so we can potentially add this feature? Feel free to follow up via. email instead of on here, if that’s what you’d like.
Hi Ewan,
Here, I’ve published the source code:
https://github.com/m417z/Multiline-Ultimate-Assembler
Enjoy 🙂